
DeepSeek本地化部署硬件配置要求一览表:
| 模型版本 | CPU | 内存 | 显卡 | 存储 | 网络 |
| DeepSeek-R1-1.5B | 任意四核处理器 | 8GB | 无需GPU | 12GB | 本地部署无需高带宽,云端需≥100Mbps |
| DeepSeek-R1-7B | Ryzen 7或更高 | 16GB | RTX 3060(12GB)或更高 | 80GB | 本地部署无需高带宽,云端需≥100Mbps |
| DeepSeek-R1-14B | i9-13900K或更高 | 32GB | RTX 4090(24GB)或更高 | 200GB | 本地部署无需高带宽,云端需≥100Mbps |
| DeepSeek-R1-32B | Xeon 8核+128GB或更高 | 64GB | 2-4张A100 80GB或更高 | 320GB | 多卡需PCIe 4.0互联,云端部署建议≥1Gbps带宽 |
| DeepSeek-R1-70B | Xeon 8核+128GB或更高 | 128GB | 8+张A100/H100,显存≥80GB/卡 | 500GB+ | NVIDIA NVLink/InfiniBand(≥200Gbps)互联 |
DeepSeek本地化部署教程如下:
一、安装:Ollama(https://ollama.com/)

根据你的操作系统选择对应的安装包进行下载。

下载安装包:根据你的操作系统选择对应的安装包。下载完成后,直接双击安装文件并按照提示完成安装。
验证安装:安装完成后,在终端输入以下命令,检查Ollama版本:
ollama --version
如果输出版本号(例如ollama version is 0.5.6),则说明安装成功。
二:下载并部署DeepSeek模型
Ollama支持多种DeepSeek模型版本,用户可以根据硬件配置选择合适的模型。以下是部署步骤:
选择模型版本:
入门级:1.5B版本,适合初步测试。
中端:7B或8B版本,适合大多数消费级GPU。
高性能:14B、32B或70B版本,适合高端GPU。
下载模型:
打开终端,输入以下命令下载并运行DeepSeek模型。例如,下载7B版本的命令为:
ollama run deepseek-r1:7b
如果需要下载其他版本,可以参考以下命令:
- ollama run deepseek-r1:8b # 8B版本
- ollama run deepseek-r1:14b # 14B版本
- ollama run deepseek-r1:32b # 32B版本
启动Ollama服务:
在终端运行以下命令启动Ollama服务:
ollama serve
服务启动后,可以通过访问 http://localhost:11434 来与模型进行交互。
为了方便对话,我们可以下载一个chatboxai (官网:https://chatboxai.app/zh)
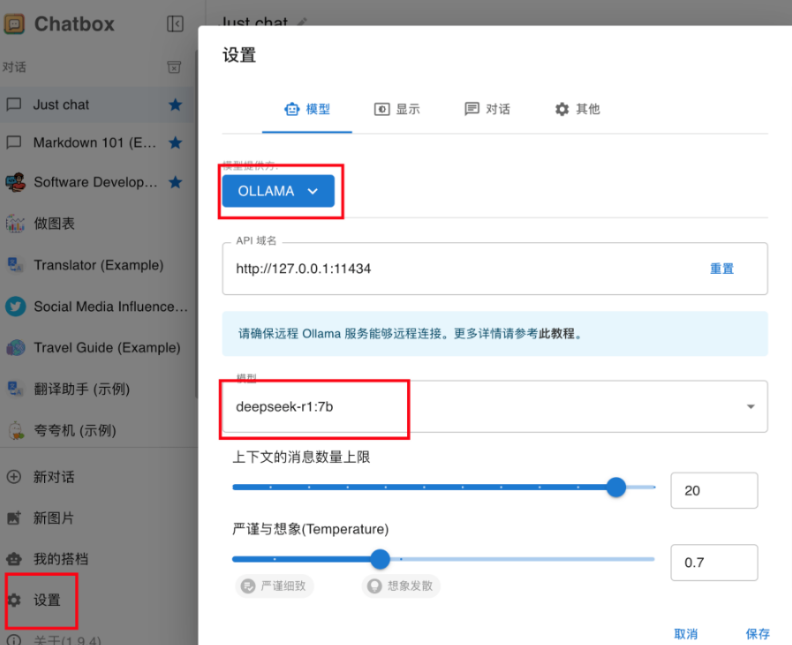
在设置中选择ollama,选择deepseekr1模型:
之后就能跟AI愉快的对话了
免责声明:本文内容,图片来源于互联网及文摘转载整编而成,不代表本站观点,不承担相关法律责任。其著作权归其原作者所有。如发现本站有侵权/违法违规的内容,侵犯到您的权益,请联系站长,一经查实,本站将立刻处理。