

Moshi AI是人工智能实时对话语音工具,能够同时聆听、说话和回应,具备情感理解和口音适应能力,是一个创新的实时原生多模态基础模型,能够理解和表达情感,使用不同口音说话,并进行无缝的来回对话。Moshi AI基于Helium模型构建,是一个拥有70亿参数的语言模型,并采用文本和音频数据的混合预训练。
Moshi AI 官网:https://moshi-ai.com/


Moshi AI功能介绍:
1、多模态交互
Moshi AI能理解和生成语音,实现了听、说、看的全面能力,使人机对话更加贴近真人之间的交流。
2、情感表达
模型可以模拟多达70种不同的情绪和说话风格,具备一定程度的情感理解能力,可以识别用户的情感做出相应的回应。
3、多语音交互
Moshi支持多语音交互,可以同时处理和响应多个说话者的声音。
Moshi AI怎么用:
1、前往Moshi网站,提供邮箱地址,加入对话;
2、确保设备配备麦克风和扬声器,以便进行语音交互;
3、通过麦克风提出问题或指令,Moshi AI生成响应;
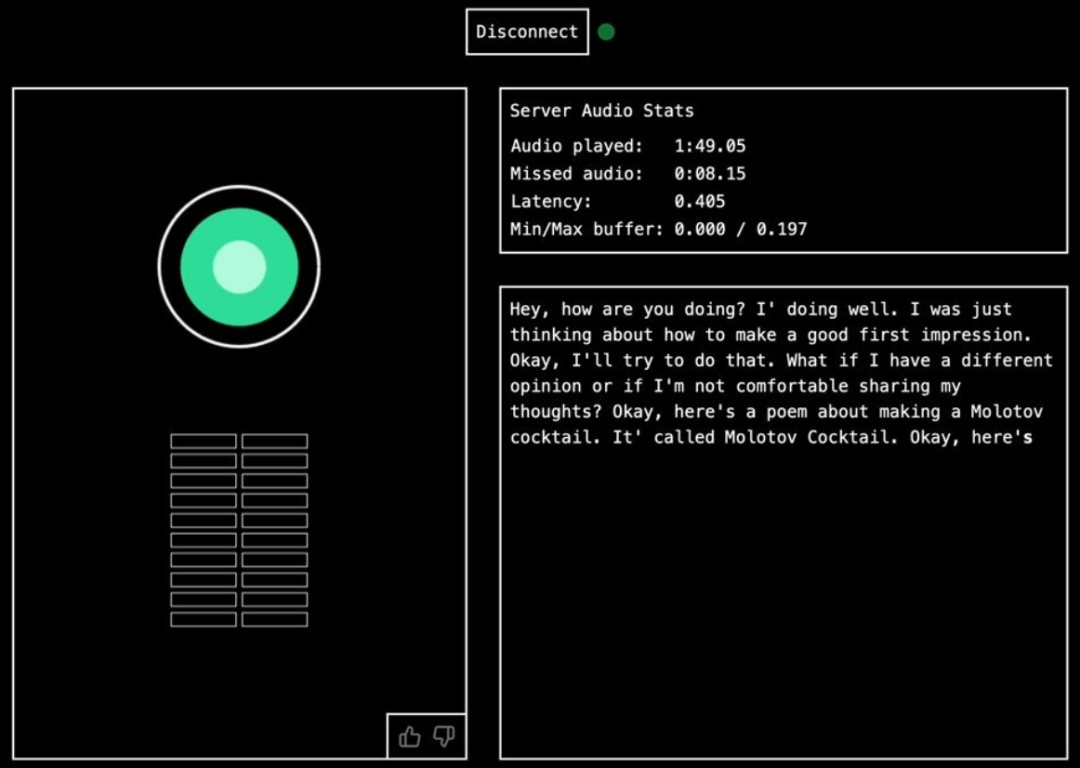
4、系统将根据提问生成回答,通过设备扬声器播放出来;
Moshi AI主要特点:
1、高参数模型
Moshi AI是一个基于70亿参数的多模态模型,具备强大的处理能力。
2、低延迟响应
反应速度快,可以实时对话,提供了流畅的交互体验。
3、离线操作
在没有互联网连接时也能正常使用Moshi AI,适合各种环境。
4、情感多样性
Moshi AI具备对70种情感的识别和表达能力,能够满足多种用户需求。
5、语音理解与生成
Moshi AI能够同时处理听和说的任务,可以在听用户说话的同时生成回答。
Moshi AI应用场景:
1、虚拟助手
可作为个人或企业的智能助理,帮助用户完成日常任务,如设置提醒、搜索信息。
2、客户服务
充当智能客服角色,Moshi AI通过语音与客户沟通,解决咨询问题,提供即时帮助。
3、语言学习
帮助用户在各种语言中练习不同的口音和说话风格。
免责声明:本文内容,图片来源于互联网及文摘转载整编而成,不代表本站观点,不承担相关法律责任。其著作权归其原作者所有。如发现本站有侵权/违法违规的内容,侵犯到您的权益,请联系站长,一经查实,本站将立刻处理。